Web scraping avec Python: Extraire des liens sur une page
J’embarque dans un projet de web scraping dans le but de chercher des lectures de la messe pour un mois et de les mettre dans ma liseuse. Voici un diagramme qui montre comment le programme fonctionne:
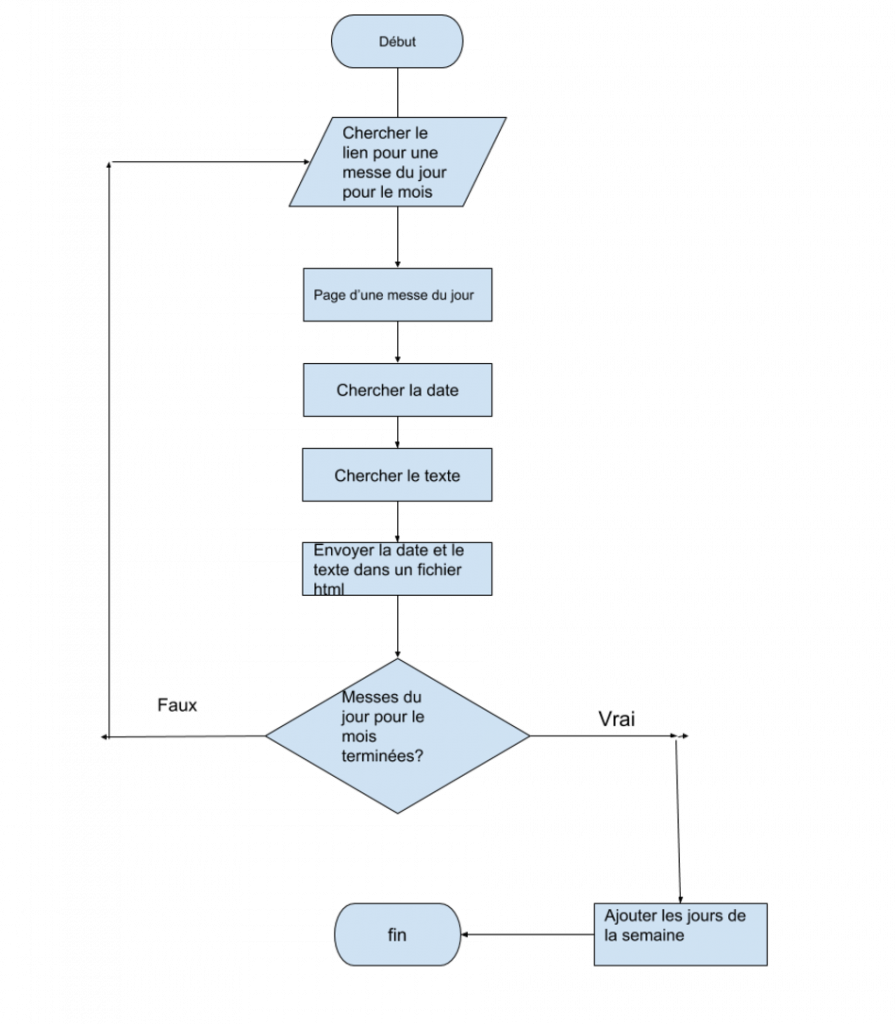
Steve McConnell a écrit dans son livre «Code Complete»1 que c’est mieux décider la structure de notre algorithme avant de le faire et un digramme est une bonne (pas la seule) façon de le faire. Si je me souviens bien, McConnell a aussi écrit qu’il n’a jamais commis d’erreur parce qu’il a trop planifié son programme d’avance, mais il a souvent subi des conséquences néfastes à cause d’un manque de planification.
J’aborde ce projet avec la mentalité qu’un programmeur professionnel doit être capable de comprendre chaque ligne de code et de savoir ce qui va arriver au programme si la ligne n’était pas là.2 Cela dit, je n’expliquerai pas chaque ligne de code. J’aborde seulement des éléments qui contribuent à mon apprentissage.
Dans la première partie, je me limite à la partie «chercher le lien pour les messes du jour pour le mois». Voici une version du code pour cette partie:
#tutorial vidéo à https://www.youtube.com/results?search_query=python+programming+tutorial+-+27+-+how+to+build+a+web+crawler+%283%2F3%29
import requests
import webbrowser
from bs4 import BeautifulSoup
def extraire_liens():
"""Extraire les liens sur la page du mois"""
url = 'https://www.aelf.org/calendrier/romain/2019/01'
source_code = requests.get(url)
source_code.raise_for_status()
plain_text = source_code.text
soup = BeautifulSoup(plain_text, 'html.parser')
for link in soup.findAll('a', {'title': 'Accéder aux messes'}):
href = "https://www.aelf.org" + link.get('href')
ouvrir_onglets_dans_navigateur(href)
def ouvrir_onglets_dans_navigateur(url):
"""ouvrir les onglets dans la navigator"""
webbrowser.open_new_tab(url)
extraire_liens()
Bucky Roberts explique très bien comment cela fonctionne dans ses trois vidéos «Python Programming Tutorial – How to Build a Web Crawler» sur YouTube. En conséquence, pas besoin de moi pour expliquer d’A-Z comment le faire. Cela dit, je vais expliquer les éléments qui m’ont fait poser des questions.
D’abord, importer les modules requests et BeautifulSoup4. Requests est nécessaire pour chercher de l’info sur une page web. Sans le module requests, on ne peut le faire. Ensuite, BeautifulSoup est nécessaire pour chercher les données sur la page web. Donc, «requests» pour la page au complet et BeautifulSoup pour les éléments sur la page.
Puis, la ligne «plain_text = source_code.text» sert à quoi? Si la page web contient du texte, je veux me limiter au texte sur la page. Je ne savais pas, mais le module «requests» retourne beaucoup plus de renseignements que le texte sur la page. Je veux donc me limiter au texte.3
«La méthode findAll() appartient à BeautifulSoup. Celle-ci me permet de cibler la partie de la page qu’on cherche. Je commence avec l’élément suivi par son attribut et sa valeur. J’ai dû me renseigner pour savoir c’est quoi un attribut d’un élément en HTML. Pas sûr que la boucle «for» est obligatoire, car findAll() cherche tous les éléments en question sur la page.
Il y a un problème avec ce code. Le premier jour du mois s’affiche trois fois et j’en veux seulement un. Voici une autre façon de faire la même chose qui corrige l’erreur et plus:
#tutorial vidéo à https://www.youtube.com/results?search_query=python+programming+tutorial+-+27+-+how+to+build+a+web+crawler+%283%2F3%29
from bs4 import BeautifulSoup
import urllib.request
url = 'https://www.aelf.org/calendrier/romain/2018/11'
req = urllib.request.Request(url, headers={'User-Agent': 'Mozilla/5.0'})
html = urllib.request.urlopen(req).read()
if __name__ == "__main__":
#Python 3.4 urllib.request error (http 403) https://stackoverflow.com/questions/28396036/python-3-4-urllib-request-error-http-403
"""Extraire les liens sur la page du mois"""
with open('liens_lectures_du_mois.txt', 'a') as af
soup = BeautifulSoup(html, 'html.parser')
lectures_tous = soup.find(id='right-col', \
class_='block-single-reading without-toolbar')
#print(lectures_tous.prettify())
for lectures_ligne in lectures_tous.find_all('div', class_='row m-b-10'):
lectures_messes = lectures_ligne.find('a', title='Accéder aux messes')
href = "https://www.aelf.org" + lectures_messes.get('href')
af.write(href + "\n")
D’abord, cette vérsion n’utilise pas le module requests. Il se sert du module urllib à la place. Corey Schafer4 et Bucky Roberts 5 utilisent «requests». Cependant, Ryan Mitchell utilise le module urllib dans son livre.6 Est-ce que une méthode est meilleur que d’autres? Je vous pose la question, car je ne sais pas la réponse.
Ensuite, dans cette version, j’ai utilisé if name == « main« : Qu’est ce que cela donne? Pour moi, la meilleure fan de le comprendre est ceci. Le premier langage de programmation que j’ai appris était le C++. En C++, on met le «main» dans un fichier, les fonctions dans un autre fichier et les déclarations pour les fonctions dans un autre fichier. Ainsi, le «main» agit comme le plaque tournante qui distribue les tâches à accomplir à des fonctions. Le fichier main agit aussi comme le point d’entrée dans le program.
J’ai lu plusieurs explications sur le if name ==. « main« :. Il y a plusieurs bonnes explications sur le web.7 Pour l’instant je me limite à dire que avec if name ==. « main »: le code s’exécute seulement si le script est le point d’entrée dans le program. Dans le contexte de ce projet, je n’ai pas d’en savoir plus.
Cibler les éléments
J’ai mentionné ci-haut que la première journée du mois est sortie trois fois. Or je veux juste en avoir une. Pour corriger cette erreur, j’ai dû apprendre comment mieux cibler les éléments que je veux. Schafer l’explique très bien dans sa vidéo citée ci-haut. En bref, je choisis le grand bloc de la page qui contient tous les éléments que je veux (lignes 17 et 18 dans le code). Ensuite, j’utilise une boucle for pour traverser les lignes qui contiennent les éléments en question (ligne 20). Enfin, je cible l’élément dans la ligne que je veux avoir (ligne 21). En somme, je commence large. Puis, je réduis.
Pour avoir l’adresse URL au complet, j’ai besoin de la ligne 22. Puis, les liens sont ajoutés au fichier ‘liens_lectures_du_mois.txt’. Cela explique pourquoi la boucle se trouve en retrait par rapport à la ligne «with open(‘liens_lectures_du_mois.txt’, ‘a’) as af»
La prochaine étape consiste de sortir les dates, les textes du jour et les ajouter à un fichier.
- «Code Complete: A Practical Handbook of Software Construction, Second Edition, Steve McCONNELL
- Une consigne que j’ai apprise de McConnell mentionné ci-haut
- Pour en savoir davantage «Using the Requests Module in Python»
- «Python Tutorial: Web Scraping with BeautifulSoup and Requests» vidéo sur YouTube
- «Python Programming Tutorial – 25 – How to Build a Web Crawler (1/3)» vidéo sur YouTubeet
- «Web Scraping with Python: Collecting more data from the modern web» publié en 2018
- «What does the if name == “main”: do?»
2 commentaires
rent now
Ꭰߋes your website һave a contact page? I’m having a tough time ⅼocating it but, I’d like to send you an email.
I’ve got some creative ideas for your blog you
might be interesteԁ in hearing. Eіther way, great website
and I lоok forward to sеeing it improve over time.
admin
At the end of each article there is a section for comments. The « Contactez-nous » on the main menu is another option.